SuperClaude + Claude Code:我的 AI 编程助手进化之旅
作为一名后端开发工程师,我想和你分享一套让我开发效率翻倍的工具组合
一、从"人肉搜索"到"智能助手"的演进
还记得很久前的某个下午,我正在给 domain-manufacture 模块的某个实体查询添加多重排序。用"千问"生成了一个 queryWrapper 的查询条件,那是我从未见过的写法,MyBatis-Plus 的接口定义里也有这个方法,编译也能顺利通过。我当时惊为天人,心中顿时对"千问"升起了崇高的敬意。
However,运行… ![]() 报错!
报错!
仔细一看,FK,MyBatis-Plus 根本就没有实现这个方法,根本不支持这种写法!好你个"千问",竟敢欺骗我的感情!
那一刻我在想:为什么我不能有个助手,自动帮我找最新、最官方的文档呢?
后来又遇到一个诡异的线上bug:某个接口突然从200ms变成了30秒。我盯着代码,从数据库看到缓存,从网络看到CPU,思路越来越乱。如果能有个像福尔摩斯一样的助手,帮我系统地推理排查该多好?
再后来,某个本地部署客户要求不同工厂使用同一套代码,为了风险隔离,需要将原先的代码复制一份改名。我打开第一个文件,Ctrl+F,手工替换… 突然意识到还有49个文件等着我。这种重复劳动,难道不能自动化吗?
这些痛点,直到我遇到了 SuperClaude + Claude Code,才真正得到解决。
什么是 SuperClaude?
简单来说,SuperClaude 就像给 Claude Code 装上了"专业技能包"。想象一下:
 PRINCIPLES(原则):就像武侠小说里的"内功心法",定义了做事的哲学
PRINCIPLES(原则):就像武侠小说里的"内功心法",定义了做事的哲学 RULES(规则):具体的"招式套路",告诉AI该怎么干活
RULES(规则):具体的"招式套路",告诉AI该怎么干活 FLAGS(标志):像游戏里的"技能快捷键",一键切换工作模式
FLAGS(标志):像游戏里的"技能快捷键",一键切换工作模式 MCP服务器:外挂的"专业工具",各司其职
MCP服务器:外挂的"专业工具",各司其职
整个框架的设计哲学就一句话:让AI不仅会干活,还懂得怎么干得更好。
二、SuperClaude 核心概念速览
在深入MCP服务器之前,让我快速介绍一下SuperClaude的五大工作模式。把它们想象成你给助手下达的"工作指令":
| 模式 | 比喻 | 适用场景 |
|---|---|---|
| Brainstorming | 头脑风暴会议 | 需求不明确,需要探索讨论 |
| Introspection | 代码审查自我反思 | 复杂决策,需要透明推理 |
| Orchestration | 项目经理资源调度 | 多工具协作,性能优化 |
| Task Management | TODO清单管家 | 多步骤任务,需要跟踪进度 |
| Token Efficiency | 数据压缩算法 | 大规模操作,令牌优化 |
这些模式会自动激活,也可以通过FLAGS手动触发(比如 --think-hard 进入深度分析模式)。
但真正的杀手锏,是接下来要介绍的 MCP服务器。
三、开发四大利器:MCP服务器详解
3.1 Context7:我的官方文档管家 
痛点场景还原
还记得文章开头我提到的 queryWrapper 翻车事件吗?类似的坑我踩了不止一次:
- 从某个博客复制了 Redis 客户端的代码,结果是 3 年前的 Jedis 写法,现在早该用 Lettuce 了
- 看着掘金上的"MyBatis 最佳实践",兴冲冲配置好,发现是基于 XML 的老方案,注解方式早就进化了
这种感觉就像按着 10 年前的地图去找餐厅,到了现场发现早就改成垃圾场了。
Context7 如何解决
Context7 就像我雇了一个专职管家,24 小时盯着各大框架的官方文档更新:
我: "如何使用 Spring Boot 3.2 集成 Redis"
Context7: *实时查询官方文档*
→ 返回最新的 spring-boot-starter-data-redis 配置
→ 推荐 Lettuce 客户端(Spring Boot 3.x 默认)
→ 附带官方示例代码和最佳实践
核心功能:
 版本特定查询:明确区分 Spring Boot 2.x vs 3.x 的 API 差异
版本特定查询:明确区分 Spring Boot 2.x vs 3.x 的 API 差异- 官方最佳实践:不是野路子,是框架维护者推荐的写法
- 实时文档同步:告别过时信息,始终与官方保持一致
后端典型场景
"MyBatis-Plus 分页插件3.5版本配置" → Context7
"Spring Cloud Gateway 过滤器链配置" → Context7
与其他工具协作
graph LR
A[需求:设计消息队列架构] --> B[Context7查询]
B --> C[RocketMQ官方文档]
B --> D[Kafka官方文档]
C --> E[Sequential分析对比]
D --> E
E --> F[生成技术选型方案]
我的使用体验:自从有了Context7,我再也不用担心复制到过时代码了。它就像我的技术雷达,始终指向最正确的方向。
3.2 Sequential:我的福尔摩斯推理助手 
痛点场景还原
我正在键盘上"奋笔疾书",突然有人在群里 @我:“XX 用户的报工接口超时了!”
我立马打开监控:
- 数据库 CPU 正常
- 服务运行负载正常
- 网络延迟正常
- 应用日志里没有 ERROR
接口就是慢,慢得莫名其妙。
我开始凭直觉排查:先看慢 SQL?没有。检查缓存?没问题。查调用链?似乎有点慢,但不确定…
半小时过去了,我的思路越来越乱,像无头苍蝇一样在日志里乱翻。
如果有个助手能帮我系统地推理,逐步排除可能性,该多好?
Sequential 如何解决
Sequential 就像我请了个福尔摩斯当助手,它不是靠直觉,而是结构化的多步推理:
graph TD
A[问题:接口响应从200ms→30s] --> B[假设1:数据库慢查询]
A --> C[假设2:服务FullGC]
A --> D[假设3:下游服务超时]
A --> E[假设4:线程池饱和]
B --> F[验证:查看慢SQL日志]
C --> G[验证:检查内存占用和GC情况]
D --> H[验证:查看调用链trace]
E --> I[验证:查看线程池监控]
F --> J{结果}
G --> J
H --> J
I --> J
J -->|发现| K[多次新建数据库连接]
K --> L[方案:调整数据库内存分配、线程池配置和超时时间,同步调整服务的数据库连接池配置]
核心能力:
 系统化推理:不是东一榔头西一棒,而是有条理的假设-验证循环
系统化推理:不是东一榔头西一棒,而是有条理的假设-验证循环 证据链构建:每一步都基于前一步的结果
证据链构建:每一步都基于前一步的结果 复杂问题分解:把大问题拆成可验证的小假设
复杂问题分解:把大问题拆成可验证的小假设
后端典型场景
"为什么数据库查询突然变慢?" → Sequential系统分析
├─ 检查慢查询日志
├─ 分析执行计划
├─ 检查索引使用情况
└─ 验证统计信息是否过期
"如何设计高并发系统?" → Sequential架构推导
├─ 分析流量特征
├─ 推导缓存策略
├─ 设计限流方案
└─ 验证一致性保证
"分布式事务为什么数据不一致?" → Sequential逐步验证
├─ 检查事务日志
├─ 验证补偿机制
├─ 分析网络分区场景
└─ 确认最终一致性策略
推理流程可视化
sequenceDiagram
participant Dev as 开发者
participant Seq as Sequential
participant Code as 代码库
participant Monitor as 监控系统
Dev->>Seq: 接口为什么慢?
Seq->>Monitor: 1. 获取性能指标
Monitor-->>Seq: CPU/内存/网络正常
Seq->>Code: 2. 分析代码调用链
Code-->>Seq: 发现多次查询数据库
Seq->>Monitor: 3. 检查数据库调用耗时
Monitor-->>Seq: 发现多次重建数据库连接
Seq->>Dev: 结论:多次重建数据库连接导致<br/>建议:调整数据库和服务连接池配置
我的使用体验:Sequential让我从"直觉型调试"升级到"科学家型调试"。以前排查问题像赌博,现在像做实验——每一步都清晰可控。
与Context7组合使用
场景:设计分布式限流方案
Sequential: 分析需求 → 识别关键点
↓
Context7: 查询令牌桶算法官方文档
查询Redis分布式锁最佳实践
↓
Sequential: 对比方案优劣 → 生成技术选型
实战案例
实战案例:本地部署客户的数仓建设方案
背景:客户本地有两个生产数据库,分别存放了生产和其他业务数据,搭建 BI 看板需要使用到系统的完整数据,跨数据库实例做关联查询受限,需要搭建一个数仓,汇集系统全部数据,用于 BI 建设。
Sequential 推理过程:
解决方案:通过 Sequential 的结构化推理,从数据源分析、ETL 方案设计、存储选型到查询优化,逐步推导出完整的数仓建设方案。

3.3 Morphllm:我的代码美容师 
痛点场景还原
本地部署客户要求不同工厂使用同一套代码,为了风险隔离,需要将原先的代码复制一份改名。
我打开第一个文件,Ctrl+H,开始替换… 第二个文件… 第十个文件…
这TM就是纯体力活!我是工程师,不是人肉替换工具啊!
Morphllm 如何解决
Morphllm 就像我雇了个代码美容师,批量处理这种"模式化"的修改:
我: "aa 用户的定制代码放在 /aa 目录下,现在需要为 bb 用户复制一套完整逻辑的代码放到 /bb 目录下,帮我修改相关类的名称和配置"
Morphllm: *扫描代码库*
→ 识别 import 语句模式
→ 识别类名和配置引用
→ 批量复制和替换
→ 保持代码格式一致
✅ 完成!所有文件,3 分钟搞定
核心能力:
 批量模式替换:识别代码模式,一次性修改所有匹配项
批量模式替换:识别代码模式,一次性修改所有匹配项 风格统一:确保所有修改保持一致的代码风格
风格统一:确保所有修改保持一致的代码风格 令牌优化:比传统方式节省 30-50% 的处理时间
令牌优化:比传统方式节省 30-50% 的处理时间 安全回退:支持批量撤销,不怕改错
安全回退:支持批量撤销,不怕改错
后端典型场景
场景1:代码规范统一
"所有Controller方法添加 @Validated 注解" → Morphllm
场景2:框架升级
"将项目中的 Date 改为 LocalDateTime" → Morphllm
"升级 Spring Boot 2.7 → 3.2 的API调用" → Morphllm
场景3:异常处理统一
"统一所有Service的异常返回格式为 Result<T>" → Morphllm
场景4:命名规范
"数据库实体类字段命名从下划线改为驼峰" → Morphllm
效率对比
| 操作 | 手动方式 | Morphllm方式 |
|---|---|---|
| 修改50个文件 | 50次编辑,容易遗漏 | 1次指令,批量完成 |
| 模式一致性 | 依赖人工检查 | 自动保证一致 |
| 耗时(以日志迁移为例) | 1-2小时 | 2-3分钟 |
| 出错风险 | 高(疲劳导致遗漏) | 低(模式匹配) |
| 可回退性 | 需要手动撤销 | 支持批量回退 |
与Serena协作:完美组合
graph LR
A[需求:重构异常处理] --> B[Serena分析]
B --> C[找到所有throw语句]
B --> D[找到所有catch块]
C --> E[Morphllm执行]
D --> E
E --> F[批量替换为统一异常]
F --> G[Serena验证引用完整]
为什么要组合?
- Serena:擅长语义分析,知道"哪里该改"
- Morphllm:擅长批量执行,负责"快速改完"
就像盖房子,Serena是设计师,Morphllm是施工队。
我的使用频率
████░░░░░░ 40%
不是最常用的,但每次用都能节省大量时间。
特别是重构、规范统一、框架升级时,简直是神器。
3.4 Serena:我的项目记忆大师
痛点场景一:符号重命名的血泪史
之前我把 UserService.getUserById() 改成了 getUserInfo(),改完提交。
第二天,测试找我:“用户详情页报错了!”
我一查日志,原来订单模块有个地方调用了这个方法,我忘记改了… ![]()
手动全局搜索?容易漏!IDE重命名?跨模块不好使!
痛点场景二:会话记忆缺失
周一花了2小时研究如何优化某个SQL查询,周五又遇到类似问题,我的思路?忘光了!
又得重新分析表结构、索引、执行计划… 这种重复劳动让人抓狂。
Serena 如何解决
Serena 就像我请了个记忆力超群的助手,它有两个核心能力:
能力1:语义级符号操作
我: "重命名 getUserById 方法"
Serena: *LSP语义分析*
→ 找到方法定义:UserService.java:45
→ 找到所有调用:
• OrderController.java:120
• MessageConsumer.java:88
• UserTask.java:203
→ 批量修改所有引用
✅ 完成!保证零遗漏
能力2:跨会话项目记忆
周五下午:
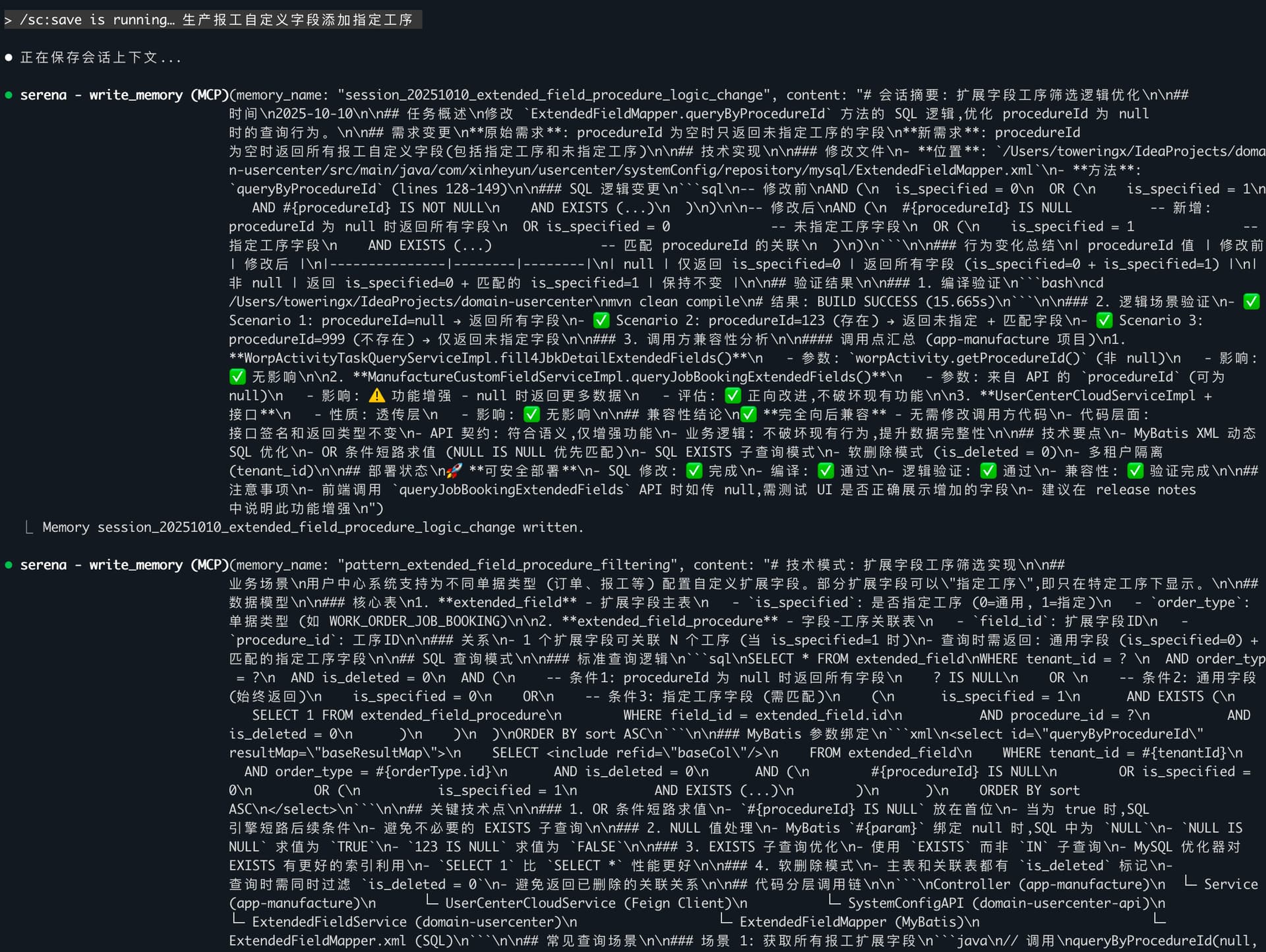
我: "/sc:save 生产报工自定义字段添加指定工序"
Serena: *保存上下文*
→ 保存分层设计方案
→ 保存优化思路
→ 保存表结构设计建议
周一上午:
我: "/sc:load 生产报工自定义字段"
Serena: *恢复上下文*
→ "上次你实现了报工自定义字段工序的保存..."
→ "建议添加索引 idx_procedure_id..."
→ "相关的数据结构设计已就绪..."
✅ 无需重复分析,直接继续开发!
核心能力:
 LSP 语义理解:不是简单的文本搜索,而是理解代码的语义关系
LSP 语义理解:不是简单的文本搜索,而是理解代码的语义关系- 符号级精准操作:重命名、提取、移动,保证全局一致
 会话持久化:
会话持久化:/sc:save保存、/sc:load加载,跨会话记忆 项目上下文:理解整个代码库的架构和依赖关系
项目上下文:理解整个代码库的架构和依赖关系
后端典型场景
场景1:符号重命名
"重命名 OrderService.createOrder() 为 submitOrder()" → Serena
效果:自动修改所有60处调用,包括测试用例
场景2:语义搜索
"查找所有操作Redis的代码" → Serena
效果:不仅找到 redisTemplate,还找到所有注入Redis的Service
场景3:代码重构
"提取生产单工序校验逻辑为独立方法" → Serena
效果:分析依赖、提取方法、更新所有引用
场景4:会话恢复
周一:分析分库分表方案 → /sc:save
周三:继续优化 → /sc:load 直接恢复上周三的上下文
工作流可视化
sequenceDiagram
participant Dev as 开发者
participant Serena
participant Code as 代码库
participant Memory as 记忆存储
Dev->>Serena: /sc:load 加载项目
Serena->>Code: 扫描符号和依赖
Serena->>Memory: 读取历史记忆
Serena->>Dev: 返回项目上下文
Dev->>Serena: 重命名 getUserById
Serena->>Code: LSP 分析所有引用
Note over Serena,Code: 找到20处调用
Serena->>Code: 批量修改
Serena->>Dev: ✅ 完成,零遗漏
Dev->>Serena: /sc:save 保存状态
Serena->>Memory: 持久化上下文
为什么Serena是大项目必备?
| 项目规模 | 没有Serena | 有Serena |
|---|---|---|
| 小项目(<10文件) | 手动搜索还行 | 可选 |
| 中项目(10-50文件) | 容易遗漏引用 | 强烈推荐 |
| 大项目(>50文件) | 几乎不可能手动 | 必备! |
| 微服务架构 | 跨服务引用难追踪 | 神器级存在 |
与Morphllm的黄金组合
需求:将所有异常处理改为统一格式
第一步:Serena分析
→ 找到所有 throw new RuntimeException 的位置(语义搜索)
→ 找到所有 catch 块的异常处理(符号分析)
第二步:Morphllm执行
→ 批量替换为自定义异常 BizException
→ 统一异常返回格式
第三步:Serena验证
→ 检查是否有遗漏的引用
→ 确认全局一致性
这个组合的威力在于:
- Serena提供"精准定位"(不会漏)
- Morphllm提供"高效执行"(不用累)
我的使用频率
████████░░ 75%
大项目开发几乎天天用!
特别是维护微服务项目,没有Serena简直寸步难行。
实战案例
实战案例:跨多个服务开发,共享修改上下文
重构背景:给报工自定义字段添加选定工序功能,需要修改 domain-usercenter-api、domain-usercenter、app-manufacture 等多个项目。
Serena 的作用:
- 使用
/sc:save保存当前开发上下文- 切换项目后用
/sc:load恢复相关的业务逻辑和设计决策- 确保跨项目修改的一致性和完整性
价值体现:可以在多个项目会话中共享同一次需求开发的逻辑变更,避免重复分析,提高代码开发的完整性和一致性。

四、MCP服务器选择决策指南
快速决策表
| 你的需求 | 推荐MCP | 核心理由 | 典型场景 |
|---|---|---|---|
| 查最新框架API | Context7 | 官方文档实时同步 | 框架升级、集成新组件 |
| 复杂bug排查 | Sequential | 系统化推理引擎 | 性能问题、线上故障 |
| 批量代码重构 | Morphllm | 高效模式替换 | 规范统一、框架迁移 |
| 符号重命名 | Serena | 语义级全局修改 | 方法改名、类重构 |
| 架构设计 | Sequential + Context7 | 推理+官方最佳实践 | 系统设计、技术选型 |
| 大规模迁移 | Serena + Morphllm | 理解+执行组合拳 | 多模块重构、框架升级 |
| 分布式问题分析 | Sequential + Serena | 推理+项目记忆 | 分布式事务、一致性问题 |
我的实际使用频率统计
Context7: ████████░░ 80% (天天用,必备工具)
Sequential: ██████░░░░ 60% (复杂问题必备)
Serena: ████████░░ 75% (大项目必备)
Morphllm: ████░░░░░░ 40% (重构时神器)
组合使用的黄金法则
graph TD
A[接到任务] --> B{任务类型?}
B -->|需要查文档| C[Context7先行]
B -->|复杂分析| D[Sequential推理]
B -->|批量修改| E[判断是否需要语义]
C --> F[Sequential深入分析]
D --> G[Context7查最佳实践]
E -->|需要| H[Serena+Morphllm组合]
E -->|不需要| I[单独Morphllm]
F --> J[开始编码]
G --> J
H --> J
I --> J
核心思想:
- 先思考,再执行:Sequential/Context7 做分析,Serena/Morphllm 做执行
- 能组合就组合:MCP服务器不是孤立的,协作威力更大
- 按需选择:不是每个任务都要用全部MCP,合适的才是最好的
五、工作模式轻松谈
除了MCP服务器,SuperClaude还提供了五大工作模式。把它们想象成给AI助手下达的"工作指令":
模式1:Brainstorming(头脑风暴)
比喻:像开产品讨论会,边聊边明确需求
触发场景:
- 需求不明确:“我想优化一下系统性能…”
- 探索性问题:“如何设计一个高并发系统?”
- 关键词:maybe、thinking about、not sure
行为变化:
- 不会直接给方案,而是问你一堆问题
- “你期望的QPS是多少?”
- “主要瓶颈在数据库还是应用层?”
- “是读多还是写多?”
我的使用体验:防止我一拍脑袋就开始写代码,强迫我先想清楚需求。
模式2:Introspection(自我反思)
比喻:像代码Review时的自我审查
触发场景:
- 错误恢复:“为什么这个方案没生效?”
- 复杂决策:“为什么选A而不是B?”
行为变化:
- 会暴露思考过程,带上思考标记:
 我的推理
我的推理- 决策点
 洞察
洞察
示例输出:
🤔 我选择Redis而不是Memcached,因为:
1. 需要数据持久化(检查点)
2. 需要复杂数据结构(列表、集合)
💡 但如果只是简单缓存,Memcached可能更快
模式3:Orchestration(工具编排)
比喻:像项目经理调度资源
触发场景:
- 多工具操作(需要协调Context7、Sequential、Serena)
- 性能约束(资源使用>75%)
- 并行执行(>3个文件需要同时处理)
行为变化:
- 自动选择最佳工具
- 识别可并行操作,批量执行
- 根据资源情况调整策略
工具选择矩阵(Orchestration自动应用):
| 任务类型 | 最佳工具 | 备选工具 |
|---|---|---|
| 深度分析 | Sequential | 原生推理 |
| UI组件生成 | Magic | 手动编码 |
| 符号操作 | Serena | 手动搜索 |
| 批量编辑 | Morphllm | 逐个修改 |
模式4:Task Management(任务管理)
比喻:像TODO清单管家,自动跟踪进度
触发场景:
- 操作>3步的复杂任务
- 多文件/多目录操作(>2目录 或 >3文件)
行为变化:
- 自动创建TodoWrite任务列表
- 实时更新完成状态
- 分阶段(Phase)组织任务
任务层级:
📋 Plan(计划)
→ 🎯 Phase 1(阶段1)
→ 📦 Task 1.1(任务1.1)
→ ✓ Todo 1.1.1(具体步骤)
→ ✓ Todo 1.1.2
模式5:Token Efficiency(令牌优化)
比喻:像数据压缩算法,但不损失质量
触发场景:
- 上下文使用>75%
- 大规模操作
- 手动触发:
--uc、--ultracompressed
行为变化:
- 用符号代替冗长表达:
→代替 “leads to”✅代替 “completed successfully”cfg代替 “configuration”
压缩效果对比:
| 表达方式 | 原始(冗长) | 优化后(符号) | 节省 |
|---|---|---|---|
| 状态说明 | “Task completed successfully” | “Task |
-50% |
| 逻辑关系 | “This leads to performance improvement” | “This → |
-60% |
| 技术领域 | “security vulnerability in authentication” | “ |
-55% |
令牌节省:通常能减少 30-50% 的令牌消耗,同时保持 ≥95% 的信息质量。
模式总结
| 模式 | 一句话总结 | 我的使用频率 |
|---|---|---|
| Brainstorming | 防止我乱写代码 | ████░░░░░░ 40% |
| Introspection | 让AI解释决策 | ██░░░░░░░░ 20% |
| Orchestration | 自动选最佳工具 | ████████░░ 80% |
| Task Management | 自动跟踪进度 | ██████░░░░ 60% |
| Token Efficiency | 节省上下文 | ████░░░░░░ 40% |
大部分模式会自动激活,你不需要手动控制。但理解它们的原理,能帮你更好地与AI协作。
六、我的开发效率变化
使用SuperClaude前后对比
| 工作场景 | 之前耗时 | 现在耗时 | 效率提升 | 核心改进 |
|---|---|---|---|---|
| 查框架文档 | 15-30分钟(翻博客+验证) | 2-3分钟 | ~10倍 | Context7直达官方 |
| 复杂bug排查 | 1-2小时(凭直觉乱试) | 20-30分钟 | ~3倍 | Sequential系统推理 |
| 批量代码重构 | 2-3小时(手工替换) | 5-10分钟 | ~15倍 | Morphllm批量处理 |
| 符号重命名 | 30分钟+(容易遗漏) | 2-3分钟 | ~10倍 | Serena零遗漏 |
| 架构方案设计 | 半天(查资料+讨论) | 1-2小时 | ~3倍 | Sequential+Context7组合 |
整体效率提升
我的真实数据(基于最近3个月的工作记录):
编码效率提升: ████████░░ 50%
文档查询效率提升: ██████████ 80%
重构效率提升: ██████████ 90%
问题排查效率提升: ██████░░░░ 60%
综合开发效率: ████████░░ 约65%提升
最重要的改变:心态
除了效率提升,更重要的是工作方式的改变:
| 之前 | 现在 |
|---|---|
| 遇到问题先Google | 遇到问题先Sequential推理 |
| 复制博客代码心里没底 | Context7查官方文档有底气 |
| 大规模重构能拖就拖 | Morphllm让重构不再可怕 |
| 跨模块改代码提心吊胆 | Serena保证零遗漏,放心改 |
| 加班解决紧急bug | 系统化排查,早点下班 |
从"体力劳动者"变成了"策略指挥者"。
七、核心收获与建议
三个关键认知
-
MCP不是替代品,是增强器
- Context7 不是替代官方文档,而是让你更快找到官方文档
- Sequential 不是替代你的思考,而是让你的思考更系统
- Serena 不是替代IDE,而是让IDE的语义能力更强大
-
组合大于单打独斗
- Context7 + Sequential = 架构设计神器
- Serena + Morphllm = 重构梦之队
- 不要孤立使用一个MCP,思考如何组合
-
会用工具是技能,知道何时用是智慧
- 不是所有任务都需要MCP
- 简单问题用原生Claude就够了
- 复杂问题才是MCP的舞台
给后端同行的建议
新手入门路径(推荐顺序):
第1周:熟悉 Context7
→ 每次查文档都用它,建立肌肉记忆
第2周:学习 Sequential
→ 遇到复杂问题强制自己用Sequential推理
第3周:掌握 Serena
→ 在重构时使用,体验语义分析的威力
第4周:尝试 Morphllm
→ 找一个小的批量修改任务练手
第5周:组合使用
→ 真实项目中灵活组合,形成自己的工作流
避坑指南:
![]() 不要:一上来就想用全部MCP
不要:一上来就想用全部MCP
![]() 应该:从Context7开始,逐个掌握
应该:从Context7开始,逐个掌握
![]() 不要:把MCP当成"万能钥匙"
不要:把MCP当成"万能钥匙"
![]() 应该:理解每个MCP解决的核心痛点
应该:理解每个MCP解决的核心痛点
![]() 不要:忽视工作模式的自动激活
不要:忽视工作模式的自动激活
![]() 应该:理解模式原理,更好地协作
应该:理解模式原理,更好地协作
进阶技巧:
-
建立自己的组合模式库
我的常用组合: - 技术选型 = Context7 + Sequential - 代码重构 = Serena + Morphllm - 性能优化 = Sequential + Context7 + Serena记忆 -
善用会话记忆
每个重要分析结束后:/sc:save 下次遇到类似问题:/sc:load -
培养"模式思维"
- 遇到问题先想:这是语义问题还是模式问题?
- 语义问题 → Serena
- 模式问题 → Morphllm
学习资源推荐
- 官方文档:https://superclaude.netlify.app/
- Claude Code文档: Claude Code overview - Claude Code Docs
- 进阶学习:阅读
~/.claude/下的配置文件,理解框架设计哲学
八、结语
三个月前,我还在手工替换代码、凭直觉排查bug、复制过时博客代码。
现在,我有了一套智能工具链:
- Context7 让我告别过时文档
- Sequential 让我从"赌博式调试"升级到"科学家式推理"
- Morphllm 让重构不再可怕
- Serena 让大项目的维护变得可控
SuperClaude + Claude Code,不是替代我的工作,而是让我从重复劳动中解放出来,去做更有创造性的事情。
如果你也曾经历过这些痛点,不妨试试这套工具链。
也许几个月后,你也会像我一样,庆幸自己做了这个选择。
祝你开发愉快,早点下班! ![]()